前言
在学习了HashMultiset后,接着学习HashBiMap,该类非常有意思,与HashMap相反,当其插入k-v的v相同时报错。猜想该类的实现是在底层将v当成k进行存储,而k当成v进行存储。
HashBiMap
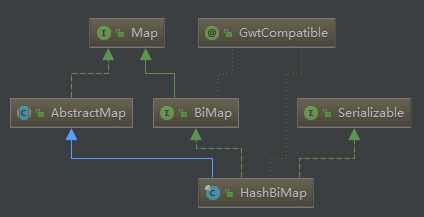
下面是HashBiMap的类结构,其继承AbstractMap和BiMap,其中AbstractMap定义了一些非结构性的操作,如get,而BiMap则定义了一些对结构进行修改的操作,如put。
示例
package com.hust.grid.leesf.guavalearning;
import com.google.common.collect.HashBiMap;
public class HashBiMapTest {
public static void main(String[] args) {
HashBiMap<String, Integer> hashBiMap = HashBiMap.create();
hashBiMap.put("leesf", 25);
hashBiMap.put("dyd", 26);
System.out.println(hashBiMap);
hashBiMap.forcePut("ld", 25);
System.out.println(hashBiMap);
}
}
运行结果
{leesf=25, dyd=26}
{ld=25, dyd=26}
init
在调用create方法创建HashMapBiMap实例时,会调用到init方法,其源码如下。
private void init(int expectedSize) {
// 检查参数
checkArgument(expectedSize >= 0, "expectedSize must be >= 0 but was %s", expectedSize);
// 寻找大于expectedSize最小的2的整数次方的数
int tableSize = Hashing.closedTableSize(expectedSize, LOAD_FACTOR);
// 创建K->V表
this.hashTableKToV = createTable(tableSize);
// 创建V->K表
this.hashTableVToK = createTable(tableSize);
// 用于确定桶位置
this.mask = tableSize - 1;
// 初始化其他变量
this.modCount = 0;
this.size = 0;
}
可以看到其首先会检查大小,必须要大于等于0;寻找最合适的表大小;创建k-v和v-k的两张表;然后初始化其他变量值,如模、大小等。
createTable
private BiEntry<K, V>[] createTable(int length) {
return new BiEntry[length];
}
其会创建长度为length,类型为BiEntry的数组。
put
调用put方法会调用put(@Nullable K key, @Nullable V value, boolean force),其中force置为false。
private V put(@Nullable K key, @Nullable V value, boolean force) {
// 获取key的hash值
int keyHash = hash(key);
// 获取value的hash值
int valueHash = hash(value);
// 在k-v桶中寻找指定BiEntry
BiEntry<K, V> oldEntryForKey = seekByKey(key, keyHash);
if (oldEntryForKey != null && valueHash == oldEntryForKey.valueHash
&& Objects.equal(value, oldEntryForKey.value)) { // 若找到并且值也相等,直接返回值
return value;
}
// 在v-k桶中寻找指定的BiEntry
BiEntry<K, V> oldEntryForValue = seekByValue(value, valueHash);
if (oldEntryForValue != null) { // 不存在
if (force) { // 强制写
// 删除老的项
delete(oldEntryForValue);
} else { // 非强制写
// 抛出异常,表示值已经存在
throw new IllegalArgumentException("value already present: " + value);
}
}
if (oldEntryForKey != null) { // 存在老的项
// 删除老的项
delete(oldEntryForKey);
}
// 创建BiEntry对象
BiEntry<K, V> newEntry = new BiEntry<K, V>(key, keyHash, value, valueHash);
// 插入
insert(newEntry);
// 判断是否需要进行重新哈希
rehashIfNecessary();
// 返回null或者老项的值
return (oldEntryForKey == null) ? null : oldEntryForKey.value;
}
可以看到,首先会根据key从k-v表中寻找项,若找到并且v相等,那么直接返回;再根据v在v-k表中寻找项,若找到并且强制写,则删除老项,若非强制写,则需抛出异常,表明v已经存在;若根据key在k-v表中寻找到项,而v不相等,则删除老项;创建新的BiEntry对象,然后插入到k-v、v-k表中;若达到再哈希条件还需进行再哈希处理。
insert
private void insert(BiEntry<K, V> entry) {
// 操作k->v表,确定桶位置
int keyBucket = entry.keyHash & mask;
// 指向下个项
entry.nextInKToVBucket = hashTableKToV[keyBucket];
// 指定桶中存放entry,都是从头部插入
hashTableKToV[keyBucket] = entry;
// 操作v->k表,确定桶位置
int valueBucket = entry.valueHash & mask;
// 指向下个项
entry.nextInVToKBucket = hashTableVToK[valueBucket];
// 指定桶中存放entry,都是从头部插入
hashTableVToK[valueBucket] = entry;
// 大小和模加1
size++;
modCount++;
}
数据会插入到两张表中,k->v插入到k-v表,v->k插入到v-k表中,都采用从头部插入方式,时间复杂度为常量。
总结
本篇博文讲解了HashBiMap的使用,其与HashMap底层存储结构十分相似,只是添加了v-k的表来判断是否v存在重复情况,当需要保证v不能重复的场景下可以使用该类。分析完java源码后再分析该类就会非常简单。